How to start your first data science project - a practical tutorial for beginners
How to start your first data science project - a practical tutorial for beginners¶
Author: Juan L. Kehoe (juanluo2008@gmail.com)
Editor: Karen Belita
Introduction¶
I'm sure everyone on the Internet is flooded by some buzz words like data science and artificial intelligence a lot in recent years. Some of you might be attracted by the sexiestjob of the 21st Century - Data Scientist [1], and want to become one. You google "how to become a data scientist" and will find tons of blog posts and articles. From the first page of the search result, you open some links and read them. You will find all of them are pretty good, with details of what a data scientist is, what kind of background do they need. Then words like linear algebra, probability, statistics, Python, R, machine learning, domain knowledge are all over you. You might be scared by how many things you will need to learn before you become a Data Scientist and you want to walk away. To be fair, all those requirements listed above are almost equivalent to the curriculum for a Ph.D. in Data Science. For a beginner, you are like a elementary school student trying to know something about Data Science, you don't need those Ph.D.-like curriculum to scare you.
Here, I'm going to show you another way to look at it. Just like to show you how to become a chef, I'm not going to list all the skills and background that you will need to become a Iron Chef, which might be your ultimate goal. But I'm going to show you a simple recipe, so you can just mix some ingredients together, do some very easy preparation, put the dish in the oven, and you will have your first experience as a chef. After your first experience y, you can decide if you enjoy the process or not. If yes, you can continue to learn more and more. Afterall, Rome is not built in one day. You can start small and then you have the chance to grow big.
In this tutorial, I'm going to use a very simple dataset (the Titanic dataset from Kaggle.com) to show you how to start and finish a simple data science project using Python and Yellowbrick, from exploratory data analysis, to feature selection and feature engineering, to model building and evaluation.
Python and Yellowbrick installation¶
Although you don't need to know how to program yet, you will still need a programming language to finish the project. If you are a chef, programming languages are the pots and pans and other stuff you need to cook. As mentioned aboce, we are going to use Python and the yellowbrick package.
Why Python and Yellowbrick¶
You can check the following link to see why we choose to use Python and Yellowbrick for our project:
https://juan0001.github.io/Why-I-use-Python-and-yellowbrick-for-my-data-science-project/
How to install Python and Yellowbrick¶
Before you use Python and Yellowbrick, you will need to install them on your computer first. The following links will show you how to install them on different operating systems:
Mac: https://youtu.be/kbDLiWRG2vk
Windows: https://youtu.be/xPqFiqIi9qs
Workflonw of a data science project¶
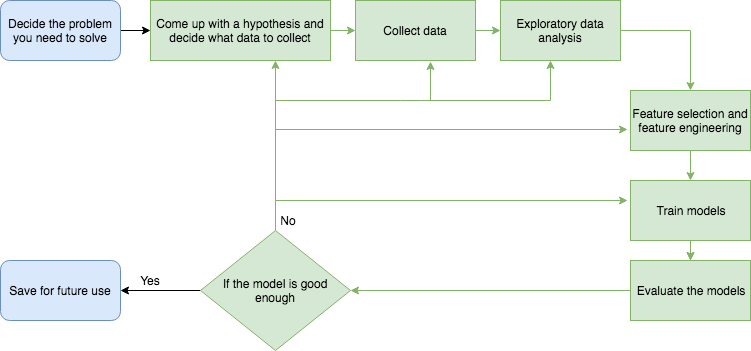
Before we start, I want to introduce you to the workflow of how to start and finish a data science project. As shown in the picture below, to start a data science project, you need to decide what the problem is. Ask yourself a question: what do you want to solve? It could be "who would survive on Titanic?" like in the example we will show below. Then you need to come up with an idea of what kind of data you will need to solve your problem, and how to collect them.
After data collection, next is exploratory data analysis (EDA). Then in the feature selection and feature engineering step, you might need to delete some features or add some new features. After you decide the features you want to feed into the model, you can start training your models.
Then you need to evaluate your models. If the models are good, you will be able to use them to predict your future data. Otherwise, you will have to go back to previous steps to do some improvement to see if you get better models. Depending on the diagnosis from your model evaluation step, you might go back to any of the previous steps and do some modifications to see if that help with your model performance.
You might need to go through the green part in the picture again and again before you get to a “good” model. There also could be the case that after you go through the green part numerous times and still could not find a good model. That's when you need to start a new project, or rethink your question.
Case study: Who would survive - Titanic dataset from Kaggle.com¶
I will show you how to start your first project via a easy example. In this project, we will use the data of the passengers and crew on Titanic to predict who survived the tragedy. We will not go through all the steps as mentioned above since it will be a simple start. We will skip the first three steps and go directly to the EDA part by using an existing dataset from Kaggle.com. It will be the Titanic dataset. Please download the data from Kaggle.
You need to put the downloaded dataset into the same folder as your Ipython Notebook file. Before you start doing anything, you can read some basic information of this dataset on Kaggle while you download the data.
Just want to let you know that I will keep my explanation in minimal which means I will not explain why we do this and that in each step. Just like when you follow a recipe to cook a cake, you just follow the steps but don't need to figure out why we use flour but not rice and other stuff too.
However, I do want you to ask a lot of questions write them down later. You can send these questions to me via email (juanluo2008@gmail.com) or comment under this post or try to figure them out yourself by googling them. And also I will attach some links in each step, if you are interested you can dig into the topics more. That way you will learn a lot beside everything from here.
Brief peek into the dataset¶
Before we do EDA, we need to peek into the dataset a little to see what's the data look like, what features do they have. The file you downloaded should be .csv files. If you google "csv file", you will know it's abbreviation for "comma-seperated values file". When you read the .csv file in by the pandas package in Python, it will read in as a table, with each line as a row and each comma separated item into different columns.
# import packages needed for the procedure
import pandas as pd
# read data as data
data = pd.read_csv("train.csv")
# check the dimension of the table
print("The dimension of the table is: ", data.shape)
As we can see above, the dimension of the table is (891, 12) which means there are 891 rows and 12 columns in the table. Each row in the table represents a passenger or a member of the crew, each column represents the information for that person which is also known as variable.
I copied the description of the features from Kaggle.com [2] as follows so we know the the information better:
Data Dictionary¶
| Variable | Definition | Key |
|---|---|---|
| survival | Survival | 0 = No, 1 = Yes |
| pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | Sex | |
| Age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | |
| parch | # of parents / children aboard the Titanic | |
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown, S = Southampton |
Variable Notes¶
pclass: A proxy for socio-economic status (SES) 1st = Upper 2nd = Middle 3rd = Lower
age: Age is fractional if less than 1. If the age is estimated, is it in the form of xx.5
sibsp: The dataset defines family relations in this way... Sibling = brother, sister, stepbrother, stepsister Spouse = husband, wife (mistresses and fiancés were ignored)
parch: The dataset defines family relations in this way... Parent = mother, father Child = daughter, son, stepdaughter, stepson Some children travelled only with a nanny, therefore parch=0 for them.
# show the first 5 rows of the data
data.head()
By showing the first 5 rows of the data, we can see the data is a mixture of numerical (PassengerId, Survivied, Pclass, Age, SibSp, Parch, Fare), categorical (Sex, Cabin, Embarked) and text data (Name, Ticket). Technically, Survivied and Pclass are categorical too, but they are represented in number form in this data. There are missing values too, which are represented as "NaN" as in the "Cabin" column.
The purpose of this project is to predict the "Survived" variable using other variables. "Survived" variable is also known as the "target" and other variables are also known as "features".
Exploratory data analysis (EDA)¶
EDA is used to explore the target and features, so we know if we will need to transform or normalize some of the features based on the distribution of them, or if we need to delete some of the features because it might not be able to give us any information in predicting future outcomes or create some new features that might be use for the prediction.
The following link is an easy introduction of EDA I liked: https://www.itl.nist.gov/div898/handbook/eda/section1/eda11.htm
It's always good if you start your EDA process by asking lots of questions. Then you can generate figures and tables to answer these question. For visulization, I will mainly use matplotlib and yellowbrick.
To start with, I will ask some simple questions and then try to fill the answers by some figures and tables. If you have more questions, feel free to write them down and try to figure out how to answer them or you can always send me an email or comment under my post.
The questions I want to ask are:
What are the variables look like:
For example, are they numerical or categorical data. If they are numerical, what are their distribution; if they are categorical, how many are they in different categories.Are the numerical variables correlated?
Are the distributions of numerical variables the same or different among survived and not survived:
Is the survival rate differnt for different values? For example, if there are more people survived if they are younger.Are there different survival rates in different categories?
For example, if there are more women survived than man.
# summary of all the numerical variable
data.describe()
For all the numerical variables, you will know the average (mean), standard deviation (std), minumum value (min), maximum value (max) and different percentile (25%, 50% and 75%) of the data. Also from the count of data, we could know that there are missing value for some of the variables. Like the "Age" variable, there are only 714 data points instead of 891.
# summary of all the objective variables (including categorical and text)
data.describe(include=['O'])
For all the objective variables (categorical and text), you can see how many categories are in each variable from the "unique" row. Like in the "Sex" variable, there are 2 categories.
Summary of all the variables in tables like this can give you very rough idea of how the variables look like. However, to check more details and have more insight of the data, we will need to deeper and use more visulization technique.
Histograms of the numerical variables¶
Histograms are very good visulization technique to check the distribution of numerical data.
In this data, "PassengerId" are unique numbers from 1-891 to label each person. And "Survived" and "Pclass" was basically categorical data. I will not plot a histogram for these variables.
# import visulization packages
import matplotlib.pyplot as plt
# set up the figure size
%matplotlib inline
plt.rcParams['figure.figsize'] = (20, 10)
# make subplots
fig, axes = plt.subplots(nrows = 2, ncols = 2)
# Specify the features of interest
num_features = ['Age', 'SibSp', 'Parch', 'Fare']
xaxes = num_features
yaxes = ['Counts', 'Counts', 'Counts', 'Counts']
# draw histograms
axes = axes.ravel()
for idx, ax in enumerate(axes):
ax.hist(data[num_features[idx]].dropna(), bins=40)
ax.set_xlabel(xaxes[idx], fontsize=20)
ax.set_ylabel(yaxes[idx], fontsize=20)
ax.tick_params(axis='both', labelsize=15)

From the histogram, we see that all the values in the variables seems in the correct range. Most of the people on the boat are around 20 to 30 years old. Most of the people don't have siblings or relatives with them. And a large amount of the tickets are less than \$50. There are very small amount of tickets are over \$500.
Barplot for the categorical data¶
Since "Ticket" and "Cabin" have too many levels (more than 100), I will not make the barplot for these variables.
# set up the figure size
%matplotlib inline
plt.rcParams['figure.figsize'] = (20, 10)
# make subplots
fig, axes = plt.subplots(nrows = 2, ncols = 2)
# make the data read to feed into the visulizer
X_Survived = data.replace({'Survived': {1: 'yes', 0: 'no'}}).groupby('Survived').size().reset_index(name='Counts')['Survived']
Y_Survived = data.replace({'Survived': {1: 'yes', 0: 'no'}}).groupby('Survived').size().reset_index(name='Counts')['Counts']
# make the bar plot
axes[0, 0].bar(X_Survived, Y_Survived)
axes[0, 0].set_title('Survived', fontsize=25)
axes[0, 0].set_ylabel('Counts', fontsize=20)
axes[0, 0].tick_params(axis='both', labelsize=15)
# make the data read to feed into the visulizer
X_Pclass = data.replace({'Pclass': {1: '1st', 2: '2nd', 3: '3rd'}}).groupby('Pclass').size().reset_index(name='Counts')['Pclass']
Y_Pclass = data.replace({'Pclass': {1: '1st', 2: '2nd', 3: '3rd'}}).groupby('Pclass').size().reset_index(name='Counts')['Counts']
# make the bar plot
axes[0, 1].bar(X_Pclass, Y_Pclass)
axes[0, 1].set_title('Pclass', fontsize=25)
axes[0, 1].set_ylabel('Counts', fontsize=20)
axes[0, 1].tick_params(axis='both', labelsize=15)
# make the data read to feed into the visulizer
X_Sex = data.groupby('Sex').size().reset_index(name='Counts')['Sex']
Y_Sex = data.groupby('Sex').size().reset_index(name='Counts')['Counts']
# make the bar plot
axes[1, 0].bar(X_Sex, Y_Sex)
axes[1, 0].set_title('Sex', fontsize=25)
axes[1, 0].set_ylabel('Counts', fontsize=20)
axes[1, 0].tick_params(axis='both', labelsize=15)
# make the data read to feed into the visulizer
X_Embarked = data.groupby('Embarked').size().reset_index(name='Counts')['Embarked']
Y_Embarked = data.groupby('Embarked').size().reset_index(name='Counts')['Counts']
# make the bar plot
axes[1, 1].bar(X_Embarked, Y_Embarked)
axes[1, 1].set_title('Embarked', fontsize=25)
axes[1, 1].set_ylabel('Counts', fontsize=20)
axes[1, 1].tick_params(axis='both', labelsize=15)

2. Are the numerical variables correlated?¶
# set up the figure size
%matplotlib inline
plt.rcParams['figure.figsize'] = (15, 7)
# import the package for visulization of the correlation
from yellowbrick.features import Rank2D
# extract the numpy arrays from the data frame
X = data[num_features].as_matrix()
# instantiate the visualizer with the Covariance ranking algorithm
visualizer = Rank2D(features=num_features, algorithm='pearson')
visualizer.fit(X) # Fit the data to the visualizer
visualizer.transform(X) # Transform the data
visualizer.poof() # Draw/show/poof the data

From the pearson ranking figure above, we can see that the correlation between variables are low (<0.5).
3. Are the distribution of numerical variables the same or different among survived and not survived?¶
# set up the figure size
%matplotlib inline
plt.rcParams['figure.figsize'] = (15, 7)
plt.rcParams['font.size'] = 50
# setup the color for yellowbrick visulizer
from yellowbrick.style import set_palette
set_palette('sns_bright')
# import packages
from yellowbrick.features import ParallelCoordinates
# Specify the features of interest and the classes of the target
classes = ['Not-survived', 'Surivived']
num_features = ['Age', 'SibSp', 'Parch', 'Fare']
# copy data to a new dataframe
data_norm = data.copy()
# normalize data to 0-1 range
for feature in num_features:
data_norm[feature] = (data[feature] - data[feature].mean(skipna=True)) / (data[feature].max(skipna=True) - data[feature].min(skipna=True))
# Extract the numpy arrays from the data frame
X = data_norm[num_features].as_matrix()
y = data.Survived.as_matrix()
# Instantiate the visualizer
# Instantiate the visualizer
visualizer = ParallelCoordinates(classes=classes, features=num_features)
visualizer.fit(X, y) # Fit the data to the visualizer
visualizer.transform(X) # Transform the data
visualizer.poof() # Draw/show/poof the data

We can see from the figure that lots of passengers with more siblings on the boat have a higher death rate. Passengers paid a higher fare survived more.
4. Are there different survival rates in different categories?¶
# set up the figure size
%matplotlib inline
plt.rcParams['figure.figsize'] = (20, 10)
# make subplots
fig, axes = plt.subplots(nrows = 2, ncols = 2)
# make the data read to feed into the visulizer
Sex_survived = data.replace({'Survived': {1: 'Survived', 0: 'Not-survived'}})[data['Survived']==1]['Sex'].value_counts()
Sex_not_survived = data.replace({'Survived': {1: 'Survived', 0: 'Not-survived'}})[data['Survived']==0]['Sex'].value_counts()
Sex_not_survived = Sex_not_survived.reindex(index = Sex_survived.index)
# make the bar plot
p1 = axes[0, 0].bar(Sex_survived.index, Sex_survived.values)
p2 = axes[0, 0].bar(Sex_not_survived.index, Sex_not_survived.values, bottom=Sex_survived.values)
axes[0, 0].set_title('Sex', fontsize=25)
axes[0, 0].set_ylabel('Counts', fontsize=20)
axes[0, 0].tick_params(axis='both', labelsize=15)
axes[0, 0].legend((p1[0], p2[0]), ('Survived', 'Not-survived'), fontsize = 15)
# make the data read to feed into the visulizer
Pclass_survived = data.replace({'Survived': {1: 'Survived', 0: 'Not-survived'}}).replace({'Pclass': {1: '1st', 2: '2nd', 3: '3rd'}})[data['Survived']==1]['Pclass'].value_counts()
Pclass_not_survived = data.replace({'Survived': {1: 'Survived', 0: 'Not-survived'}}).replace({'Pclass': {1: '1st', 2: '2nd', 3: '3rd'}})[data['Survived']==0]['Pclass'].value_counts()
Pclass_not_survived = Pclass_not_survived.reindex(index = Pclass_survived.index)
# make the bar plot
p3 = axes[0, 1].bar(Pclass_survived.index, Pclass_survived.values)
p4 = axes[0, 1].bar(Pclass_not_survived.index, Pclass_not_survived.values, bottom=Pclass_survived.values)
axes[0, 1].set_title('Pclass', fontsize=25)
axes[0, 1].set_ylabel('Counts', fontsize=20)
axes[0, 1].tick_params(axis='both', labelsize=15)
axes[0, 1].legend((p3[0], p4[0]), ('Survived', 'Not-survived'), fontsize = 15)
# make the data read to feed into the visulizer
Embarked_survived = data.replace({'Survived': {1: 'Survived', 0: 'Not-survived'}})[data['Survived']==1]['Embarked'].value_counts()
Embarked_not_survived = data.replace({'Survived': {1: 'Survived', 0: 'Not-survived'}})[data['Survived']==0]['Embarked'].value_counts()
Embarked_not_survived = Embarked_not_survived.reindex(index = Embarked_survived.index)
# make the bar plot
p5 = axes[1, 0].bar(Embarked_survived.index, Embarked_survived.values)
p6 = axes[1, 0].bar(Embarked_not_survived.index, Embarked_not_survived.values, bottom=Embarked_survived.values)
axes[1, 0].set_title('Embarked', fontsize=25)
axes[1, 0].set_ylabel('Counts', fontsize=20)
axes[1, 0].tick_params(axis='both', labelsize=15)
axes[1, 0].legend((p5[0], p6[0]), ('Survived', 'Not-survived'), fontsize = 15)

As we can see from upper figures, there are more female survived. And the death rate in the 3rd ticket class and the embarkation from Southampton port is much higher than the others.
Feature selection and feature engineering¶
In this step, we will do lots of things to the features, such as drop some features, filling the missing value, log transformation, and One Hot Encoding for the categorical features.
Features we will not use in our model¶
We will delete the features "PassengerId", "Name", "Ticket" and "Cabin" from our model. The reasons are as follows:
- "PassengerId": just a serires of numbers from 1 - 891 which is used to label each person.
- "Name": the names of all the passengers, which might give some information like if there are some people are related based on the last names. But to simplify things up at this stage, I will pass this feature.
- "Ticket" and "Cabin": too many levels with unknown information.
Filling in missing valuess¶
From EDA, we know there are some missing value in "Age", "Cabin" and "Embarked" variables. Since we are not going to use "Cabin" feature, we will just fill "Age" and "Embarked". I will fill the missing value in "Age" using the median age and fill the missing value in "Embarked" with "S" since there are only 2 values missing and "S" is the most represent in the dataset.
If you want to know more about missing data, there is a article I liked that is very easy to read: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3668100/
Just want to mention that from here on I will use functions for data preprocessing so you can reuse them on new test data without the pain of going through all the process again. And also, these functions can be used to generate pipelines to make things even easier.
# fill the missing age data with median value
def fill_na_median(data, inplace=True):
return data.fillna(data.median(), inplace=inplace)
fill_na_median(data['Age'])
# check the result
data['Age'].describe()
# fill with the most represented value
def fill_na_most(data, inplace=True):
return data.fillna('S', inplace=inplace)
fill_na_most(data['Embarked'])
# check the result
data['Embarked'].describe()
Log-transformation of the "Fare"¶
From the histograms, we can see that the distribution of "Fare" is highly right-skewed. For dealing with highly-skewed positive data, one of the strategies that can be used is log-transformation, so the skewness will be less. Since the minimum is 0, we will add 1 to the raw value, so there will not be any errors when using log-transformation.
# import package
import numpy as np
# log-transformation
def log_transformation(data):
return data.apply(np.log1p)
data['Fare_log1p'] = log_transformation(data['Fare'])
# check the data
data.describe()
# check the distribution using histogram
# set up the figure size
%matplotlib inline
plt.rcParams['figure.figsize'] = (10, 5)
plt.hist(data['Fare_log1p'], bins=40)
plt.xlabel('Fare_log1p', fontsize=20)
plt.ylabel('Counts', fontsize=20)
plt.tick_params(axis='both', labelsize=15)

We can see from the figure above, after log-transformation the data is much less skewed.
One Hot Encoding for the categorical features¶
I will use One Hot Encoding one the categorical features to transform them into numbers. If you want to know more about One Hot Encoding, there's a Quora question you can follow: https://www.quora.com/What-is-one-hot-encoding-and-when-is-it-used-in-data-science
# get the categorical data
cat_features = ['Pclass', 'Sex', "Embarked"]
data_cat = data[cat_features]
data_cat = data_cat.replace({'Pclass': {1: '1st', 2: '2nd', 3: '3rd'}})
# One Hot Encoding
data_cat_dummies = pd.get_dummies(data_cat)
# check the data
data_cat_dummies.head()
Model training and model evaluation¶
Here I will put model training and model evaluation in one part since yellowbrick is a very good package that can wrap the model and creates good visulization of the model performance which makes the model evaluation much easier and fun.
Prepares data for the model training and evaluation¶
Before we train the model, we will need to split the data into 2 sets: training and validation. We will use the training dataset to train the model and use the validation dataset to evaluate the model.
If you want to know more about training, and validation data, please check the following link: https://stats.stackexchange.com/questions/19048/what-is-the-difference-between-test-set-and-validation-set
# create a whole features dataset that can be used for train and validation data splitting
# here we will combine the numerical features and the dummie features together
features_model = ['Age', 'SibSp', 'Parch', 'Fare_log1p']
data_model_X = pd.concat([data[features_model], data_cat_dummies], axis=1)
# check the data
data_model_X.head()
# create a whole target dataset that can be used for train and validation data splitting
data_model_y = data.replace({'Survived': {1: 'Survived', 0: 'Not_survived'}})['Survived']
# check the data
data_model_y.head()
# seperate data into training and validation and check the details of the datasets
# import packages
from sklearn.model_selection import train_test_split
# split the data
X_train, X_val, y_train, y_val = train_test_split(data_model_X, data_model_y, test_size =0.3, random_state=11)
# number of samples in each set
print("No. of samples in training set: ", X_train.shape[0])
print("No. of samples in validation set:", X_val.shape[0])
# Survived and not-survived
print('\n')
print('No. of survived and not-survived in the training set:')
print(y_train.value_counts())
print('\n')
print('No. of survived and not-survived in the validation set:')
print(y_val.value_counts())
Model training and evaluation visulization using yellowbrick¶
For the purpose of this project is to predict if one passenger was survived or not, it's a classification problem. There are lots of algorithms that can be used to do classification modeling. Here I will use logistic regression.
And the following link introduced some machine learning algorithms in a way that is very easy to understand: https://towardsdatascience.com/10-machine-learning-algorithms-you-need-to-know-77fb0055fe0
There are lots of evaluation metrics you can use to evaluate your model for classification problem. Here I will use Confusion Matrix, precision, recall, F1 score, and ROC curve. Here are some links about those evaluation matrix:
- Confusion Matrix, precision, recall: https://www.sanyamkapoor.com/machine-learning/confusion-matrix-visualization/
- F1 score: http://blog.exsilio.com/all/accuracy-precision-recall-f1-score-interpretation-of-performance-measures/
- ROC curve: https://classeval.wordpress.com/introduction/introduction-to-the-roc-receiver-operating-characteristics-plot/
Confusion Matrix¶
# import packages
from sklearn.linear_model import LogisticRegression
from yellowbrick.classifier import ConfusionMatrix
from yellowbrick.classifier import ClassificationReport
from yellowbrick.classifier import ROCAUC
# Instantiate the classification model
model = LogisticRegression()
#The ConfusionMatrix visualizer taxes a model
classes = ['Not_survived','Survived']
cm = ConfusionMatrix(model, classes=classes, percent=False)
#Fit fits the passed model. This is unnecessary if you pass the visualizer a pre-fitted model
cm.fit(X_train, y_train)
#To create the ConfusionMatrix, we need some test data. Score runs predict() on the data
#and then creates the confusion_matrix from scikit learn.
cm.score(X_val, y_val)
# change fontsize of the labels in the figure
for label in cm.ax.texts:
label.set_size(20)
#How did we do?
cm.poof()

As we can see from the confusion matrix, the accuracy of the model is (158+68) / (158+24+18+68) = 84.33%. It's much higher than random guess, which is 50.00%. If you use majority guess, the accuracy will be a little higher which is 176/268 = 65.67%, but still lower than our model. It seems like our model worked pretty well which means we should use a machine learning model to predict who survived in this instance.
Precision, recall and F1 score¶
# set the size of the figure and the font size
%matplotlib inline
plt.rcParams['figure.figsize'] = (15, 7)
plt.rcParams['font.size'] = 20
# Instantiate the visualizer
visualizer = ClassificationReport(model, classes=classes)
visualizer.fit(X_train, y_train) # Fit the training data to the visualizer
visualizer.score(X_val, y_val) # Evaluate the model on the test data
g = visualizer.poof() # Draw/show/poof the data

The precision, recall, and F1 score result further confirmed that the model is relatively good.
ROC curve and AUC¶
# Instantiate the visualizer
visualizer = ROCAUC(model)
visualizer.fit(X_train, y_train) # Fit the training data to the visualizer
visualizer.score(X_val, y_val) # Evaluate the model on the test data
g = visualizer.poof() # Draw/show/poof the data

The ROC curve is also another way to show how good the model is. The doted diagonal line in the pictures shows when the result is randomly guessed. A good model should be above that line.
Conclusion¶
I briefly introduced what the workflow of a data science project should be like and using the Titanic dataset from Kaggle.com to show you how to finish a simple project. But it's not over yet. Although the model we trained looked good already, there are still a lot of opportunity to improve.
You can do lots of things to make the result looking better. I will list some possible things you can try later to see if that help with the predicting result:
- Go back to the features I discarded to see if you can dig out more information from there.
- Go to the logistic regression method on scikit-learn website to try the other parameters listed on the method to see if the model get improved.
- Try other classification algorithms to see if the performace get better.
As I mentioned in the data science project workflow section of this tutorial, you can always go back to any of the steps before model evaluating and tweak something there and see if any of the changes help your model get better.
Just a reminder, no matter what change you make, make sure to write that down and record the performance.
Also if you have other ideas, don't be afraid to try.
However, in terms of a good model, there are lots of other things you will need to know in addition to the evaluation metrics I mentioned above. I will have another post discuss about that. Please keep posted.
If you want to know when my next post will be out, you can check my website or you can follow me on Twitter.
I will also attach a block of code below to show you how to use the test.csv data you downloaded from kaggle.com so you can upload your result to see how do you do compared with other data scientists. You can also check their discussion forum to get ideas of how to improve your model and other stuff.
Anyway, hope you enjoy walkthrough with this tutorial.
Some useful learning material¶
Below are some of the learning material I used that are very simple and easy to understand for beginners.
How to become a data scientist?¶
I highly recommend William Chen's answer on Quora. He listed all the details of what you need to become a data scientist. The thing for you now is you don't have to panic and try to start from the beginning and learn everything he listed. You can treat it as a guidance or toolkit and go back to it whenever you feel stuck on your project and try to see what you can do to improve yourself as data scientist.
The link: https://www.quora.com/How-can-I-become-a-data-scientist-1/answers/4451343?share=1
Data science course¶
CS109 Data science course from Harvard University is a very good course for you to start to know structured knowledge about data science. And it also has the labs for using Python to finish data science problems which could enhance both your skills on Python and data science.
The link: http://cs109.github.io/2015/
Machine learning basics¶
Personally I think Andren Ng's machine learning course on Coursera.org is best introductory course if you want to know some machine learning as a biginner.
The link: https://www.coursera.org/learn/machine-learning
Math basics¶
The videos from 3Blue1Brown explained lots of linear algebra, caculus and other math concept in a fun and easy to understand way. I really enjoyed watching their videos.
Youtube link: https://www.youtube.com/channel/UCYO_jab_esuFRV4b17AJtAw/featured Homepage Website: https://www.3blue1brown.com/
Create a prediction dataset for submision on Kaggle.com¶
# read the test.csv data
test = pd.read_csv('test.csv')
# do the data preprocessing to make the data ready for use in a model
# fill in missing value in Age and Fare with median data
fill_na_median(test['Age'])
fill_na_median(test['Fare'])
# fill in missing value in Embarked with most represented data
fill_na_most(test['Embarked'])
# log-transform of the Fare variable
test['Fare_log1p'] = log_transformation(test['Fare'])
# One Hot Encoding
test_cat = test[cat_features] # Note: the cat_features is from previous steps
test_cat = test_cat.replace({'Pclass': {1: '1st', 2: '2nd', 3: '3rd'}})
test_cat_dummies = pd.get_dummies(test_cat)
# create a whole features dataset that can be used for predicting
# here we will combine the numerical features and the dummie features together
test_model_X = pd.concat([test[features_model], test_cat_dummies], axis=1) # note: the features_model are from previous step
# Train a model
data_model_X = pd.concat([data[features_model], data_cat_dummies], axis=1)
data_model_y = data['Survived']
model.fit(data_model_X, data_model_y)
# predict survived or not for the test data
predict = model.predict(test_model_X)
# Put the PassengerId and predicted probability together to generate submission data
LR_submission1 = pd.DataFrame({'PassengerId': test['PassengerId'], 'Survived': predict})
# Save your result
LR_submission1.to_csv('LR_submission1.csv', index=False)
Videos related with this tutorial¶
My friend, Adam Morris, who is also a volunteer in the Yellowbrick Research Labs (Spring 2018), made videos related with this tutorial. You can check these videos on his Youtube Channel.